Case Control Studies
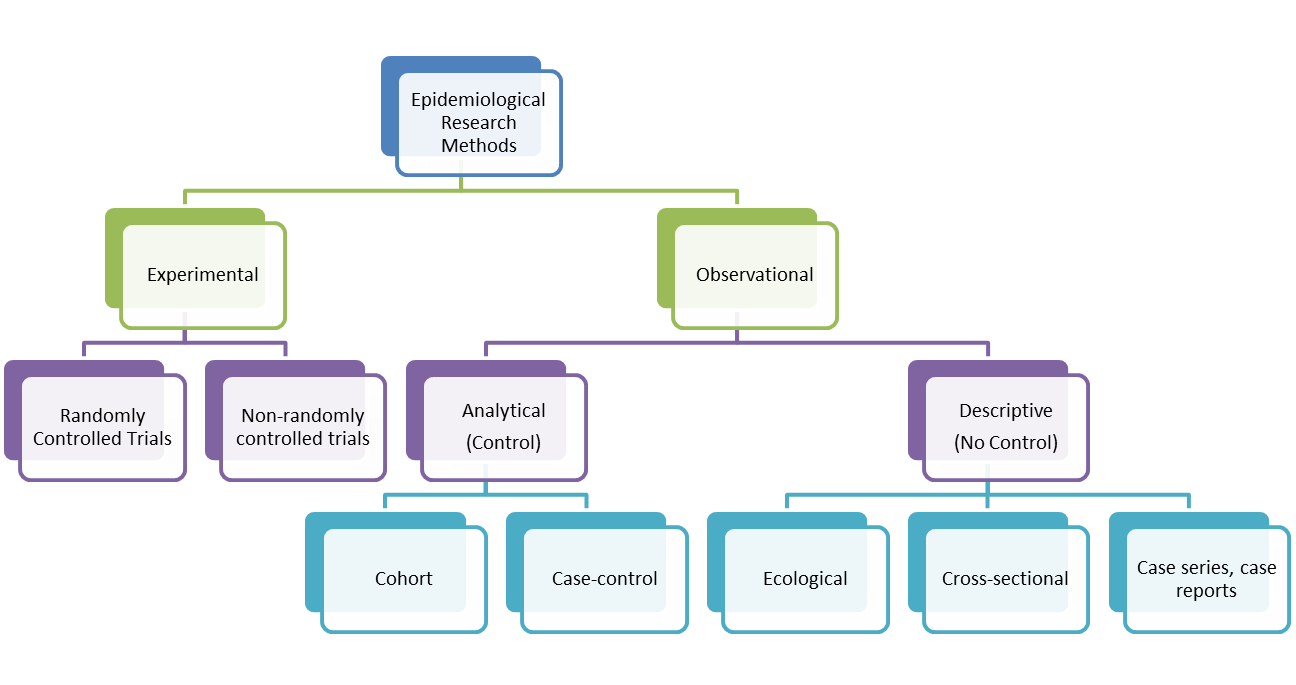
What are Case Control Studies?
A case-control study is an epidemiological study design called an observational study. Observational studies differ from experimental studies in that the researcher does not control the assignment of people to groups. Instead the groups are 'observed'. Unlike experimental studies, observational studies do not look at the effectiveness of an intervention. A case-control study is an analytical observation study, i.e. it has a comparsion (control) group. Case control studies are retrospective. They should not be confused with historical cohort studies (also retrospective). Cohorts track people forward in time from exposure to outcome. Case-control studies trace backwards from outcome to exposure. Starting with an outcome like disease, a case-control study looks backwards in time for exposures that might have caused the outcome. While cohort studies are sampled according to exposure, characteristic or cause, case-control studies are sampled according to disease or outcome. Controls are a group without the defined outcome and are compared to cases, the group with the defined outcome.
Case-control studies are hard to do well and easy to do badly! They can yield important scientific findings with relatively little time, money and effort compared with other study designs. Unfortunately, they tend to be more susceptible to biases than cohort studies. Outbreaks of food borne diseases are often examined by case-control studies. On a cruise ship, the population at risk is known. Those with vomitting and diarrhoea are asked about food exposures as are those who were not ill. If a higher proportion of those ill report having eaten a food than those well, the food becomes suspect. Sometimes a case-control study is nested within a cohort study. For example, there could be a propective study on whether low blood selenium predicts high risk of cancer. Blood samples can be taken at baseline and frozen. Participants are followed up and collection of mortality data is obtained. At the end of the study, cases and controls are defined and selenium is measured in stored samples of cases and sample of controls only.
Purpose of Case Control Studies
- To determine whether or not an association exists between a disease and a particular risk factor.
- To start with a group of people with disease and work back to see whether a possible risk factor may be the cause.
- It may be the first step in testing a hypothesis. If positive, it can then be tested in a cohort study.
Five steps in conducting a case-control study
1. Define a study population (source of cases and controls)
Controls must have as similar a background as possible to the cases, except that they do not have the outcome in question. They should come from the same population as the cases. Their selection should be independent of the exposures of interest. Objective measures of the presence of risk factors are best, ideally carried out in a 'blind' assessment or before the cases and controls are identified (i.e. they do not know who is a control or not).
2. Define and select cases
Identification of cases can be made from the general population using health register and data or from a particular medical setting. The criteria for diagnosis of a case should be defined as well as the eligibility criteria used for selection. The diagnostic criteria should be sensitive and specific (i.e. strict!). Information on diseases can be got from death certificates, disease registers, medical records or population survey. For rare diseases, cases may have to sought from large areas or over many years.
3. Define and select controls
This is a very important step. Get this wrong and you introduce bias into the study. Controls should represent the population that the cases come from (i.e. they should be at risk of becoming new cases). Ratio to cases is usually 1:1. If cases are limited, you can have up to 4 controls: 1 case. Some time will be needed in considering the way in which the cases and controls, which make up the study will be chosen. More heterogeneity in the cases, less likelihood of being able to link a specific risk factor to the disease causation. But, narrower the category of disease for inclusion as 'cases', less general applicability the findings will have.
Source of Controls: Hospital
People have taken controls from a hospital population because they maintain that the controls are in some way matched to the hospital cases. However, they are people with other risk factors. (For example, you could be comparing people with lung cancer with people with broken legs. People who break their legs are not the same as all those who develop lung cancer). The controls may have different diseases to the cases, which may have an effect on the results.
Advantages of using hospital controls:
- They are comparable to cases in regards to recall of exposure;
- They are easy to access and information is gathered in a similar way to the cases;
- They may be more willing to take part than healthy controls from the general population.
Disadvantages of using hospital controls:
- They are not typical of healthy controls in regard to a variety of exposures;
- You need to exclude diseases known to be associated with exposure of interest.
Source of controls: General Population (Community Controls)
Controls can be taken from the community the cases are from or from a different population. The controls may be healthy or may have other diseases. It is worth bearing in mind a couple of weaknesses with community controls. Healthy controls have less reliable recall of exposure. They may also be less motivated to take part and so may have lower response rates.
4. Measure exposure
The measurement of the exposure(s) must be collected in a comparable way for cases and controls. It is worth 'blinding' the data gatherers to case or control status of participants or at least blind them to the main hypothesis of the study. This should help prevent measurement or researcher bias. Exposure information can come from records (though, obvious disadvantage is that records can be inaccurate, incomplete and were not originially collected for the study purposes) or can be via an interview or questionnaire (this can introduce recall bias, where cases have more vested interest in recalling the exposures than controls, and sometimes rely on 'proxy' respondents, e.g. carers, or parents of children).
5. Estimate disease risk associated with exposure
Traditionally, data from case control studies are set in a 2 by 2 or fourfold table. It is unlike cohort studies (where study population is denominator adn incidence rate can be calculated for the disease as people are affected adn relative risk can be calculated). Because there is no population based data in case-control studies, results are best expressed as odds ratio (the ratio of exposed to non-exposed in the case group divided by the same ratio in the control group). When the number with disease is small compared with the number unaffected, the odds ratio is closer in value to the relative risk, which is a population-based estimate derived from cohort studies.
Things to watch out for!
Confounding factors
Confounding factors or variables are variable other than the risk factor, for which cases and control groups differ, age is the most common example. The possiblity of unknown confounding variables makes it difficult to state categorically that a factor is a cause. Confounding should be addressed either in the design stage or with analytical techniques. In the design stage, confounding can be controlled for by restriction or matching. Many researchers prefer to handle it in the analysis phase with analytical techniques like logistic regression or by stratification with Mantel-Haenszel approaches.
Matching
Matching of cases and controls can eliminate the matched parameter as a cause of difference. Controls are matched to cases on the basis of certain characteristics, which are also known to be present in the cases. The purpose is to eliminate confounding variables (factors in addition to the risk factor that influence whether disease occurs). If such confounding factors are unevenly distributed between study groups, they can distort comparsions and the conclusions being made. Age is a common confounder (standardisation can be used). Matching should be used sparingly. The tendency is to match in analysis of results rather than in the design stage. Overmatching occurs if a variable matched could, in fact be an intermediate on a casual pathway. This would mask a disease association.
Bias
Bias is a systematic error in the estimate of an association between cause and effect. It may result from poor diagnosis/diagnostic criteria, poor case choice, poor choice of controls or variation in the way risk exposure is measured in case and controls.
Advantages
1. Quicker, cheaper and require less time and effort than cohort studies
2. Case-control studies can study rare diseases
3. Case-control studies can study multiple risk factors/exposures
4. They are useful for studying outcomes (diseases) that take a long time to develop, e.g. cancer
Disadvantages
1. Case-control studies are prone to selection and recall bias (i.e. better recollection of exposure amongst cases than among controls
2. They are inefficient for examining rare exposures
3. It may be difficult to establish temporality (when the person was actually exposed to the disease/risk factor)
4. It can be difficutl to choose an appropriate control group
5. Unlike cohort studies, case-control studies cannot calculate incidence rates, relative risks or attributable risks. Instead odds ratio are the measure of association used (when outcome is uncommon, e.g. most cancers, it can be a good proxy for the true relative risk)
Calculating Sample Size for Case Control Studies
1. Size of 'effect' to be detected
2. Statistical significance level
3. Power of study (usually 0.8 or 0.9)
4. Ratio of 1 group to the other (exposed Vs unexposed; cases Vs controls)
Further Reading
Schultz, K.F. & Grimes, D.A. (2002) "Case-control studies: research in reverse". The Lancet, 359, 431-34.
Pearce N. Classification of Epidemiological Studies.Int J Epidemiol (2012) 41 (2): 393-397. (This article talks about there really only being 4 types of epidemiological studies: incidence studies, prevalance studies, incidence case-control studies and prevalance case control studies. The differences being the outcome and whether or not you sample on outcome).